1 min to read
[Apache Spark] Docker 기반 Zeppelin Notebook에서 Scala Spark 공부하기 (1)
Docker, Scala, ApacheSpark, Zeppelin, DataEngineering

[Spark] Docker 기반 Zeppelin Notebook에서 Scala Spark 공부하기 (1)
1. Docker란?
- Docker란 Go 언어로 작성된 오픈소서 가상화 플랫폼으로서 리눅스 컨테이너 기반으로 작동한다. 이미지와 컨테이너 개념으로 이루어져있는데, 자세한 사항은 구글링을 추천…
2. Zeppelin 설치
-
도커에 Zeppelin 이미지를 설치하고 설치된 이미지에서 컨테이너를 생성하는 방식이다.
-
mac OS 기준으로 terminal에서 아래 명령어를 실행해보자.
docker run -p 4040:4040 -p 8080:8080 --privileged=true -v $PWD/logs:/logs -v $PWD/notebook:/notebook -e ZEPPELIN_NOTEBOOK_DIR='/notebook' -e ZEPPELIN_LOG_DIR='/logs' -d apache/zeppelin:0.8.1 /zeppelin/bin/zeppelin.sh
위 코드는 zeppelin 0.8.1 버젼의 이미지를 다운받아 컨테이너를 열고 notebook, logs 디렉토리를 생성하고 4040 및 8080 포트를 사용하는 명령이다.
-
Docker Desktop에서 cli 실행 시 sudo 기능이 애초에 먹히지 않으므로 terminal에서
docker exec -itu 0 a8a8a3619788 /bin/bash등으로 직접 접근하는 것을 추천한다. -
localhost:8080으로 접근하면 아래와 같이 Jupyter 노트북과 비슷한 화면이 뜨는데 여기가 바로 Zeppelin Notebook의 메인 페이지다.
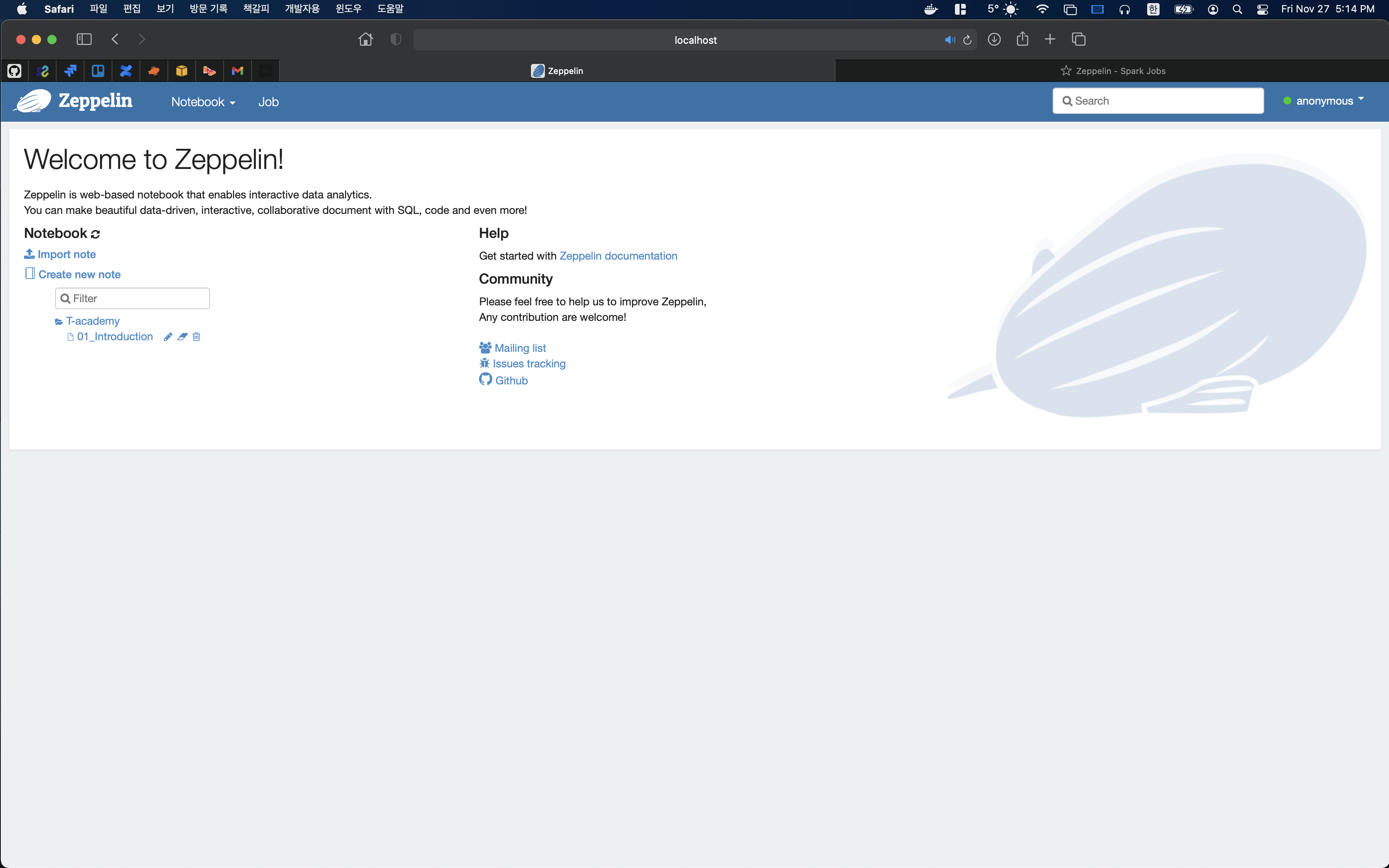
- anonymous로 접근하기 싫다면 해당 container에 아이디를 등록하여 user로 접근할 수 있다. 다만 sudo, vim 등이 설치되어 있지 않기 때문에 각각 설치할 필요가 있다.
apt-get update
->
apt-get install sudo
->
sudo apt-get install vim
mv shiro.ini.template shiro.ini또는cp shiro.ini.template shiro.ini로 shiro.ini 내부의 [users]를 아래처럼 설정한다.
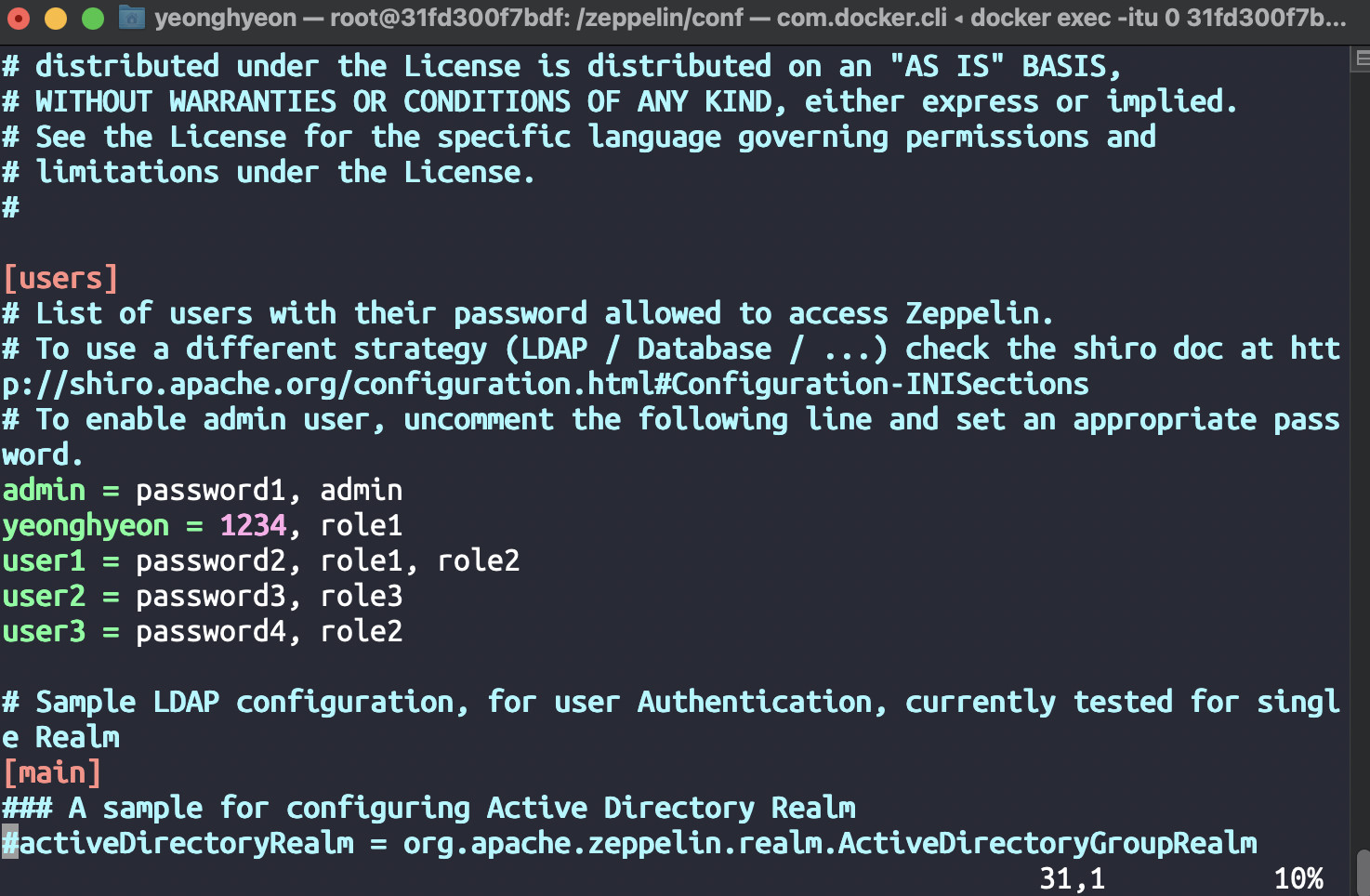
- 이제 기본적인 세팅을 끝냈으니 본격적으로 Scala Spark를 다뤄보자.

Comments